De uitgestoken hand
OTL-conforme data beheren met Python.
Omdat Python een open source taal is die gemakkelijk aan te leren is, waardoor het een populaire toepassing is voor Big Data, Machine Learning en AI projecten, heeft onze collega David Vlaminck een set van open source Python bibliotheken ontwikkeld die je kan helpen om OTL-conforme data te beheren.
Via Jupyter notebook bestanden kan je in je webbrowser experimenteren met de bibliotheken. Hierin kan je het volledige OTL-model uploaden, assets invullen en aanmaken, door eenvoudige instructies te geven met scripts. Zo kan je kennismaken met de verschillende soorten assets en hun attributen. Het handige hieraan is dat de bibliotheek meteen je invoer ten opzichte van de OTL valideert.
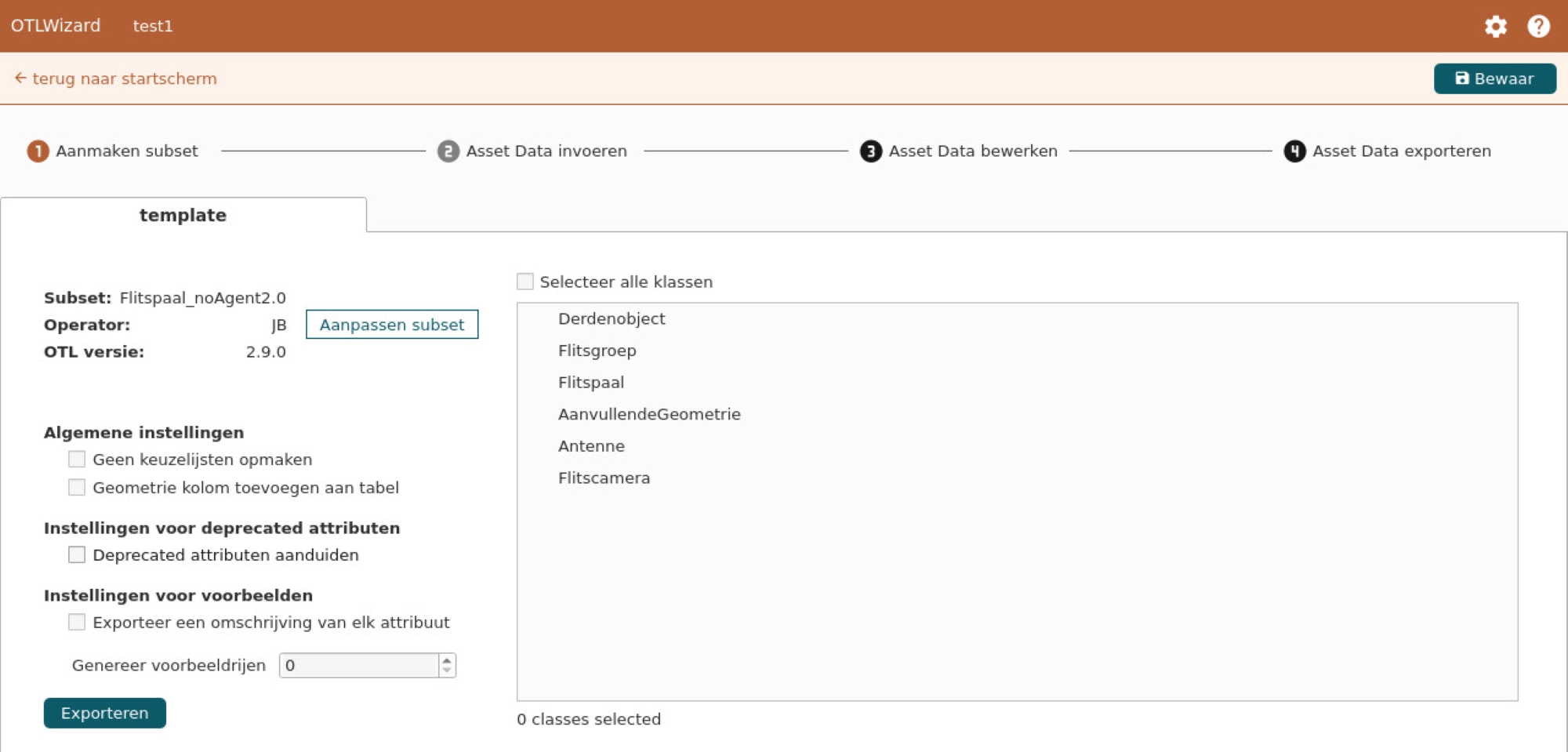
Vervolgens kan je via de converter module eenvoudig tekstuele bestanden met asset data inladen en valideren. Op die manier kan je al een check doen alvorens je een upload in ons DAVIE-dataportaal start. De ingelezen data kan je vervolgens aanpassen en exporteren naar een tekstueel bestandsformaat en je hebt de mogelijkheid om template-bestanden te genereren op basis van een subset.
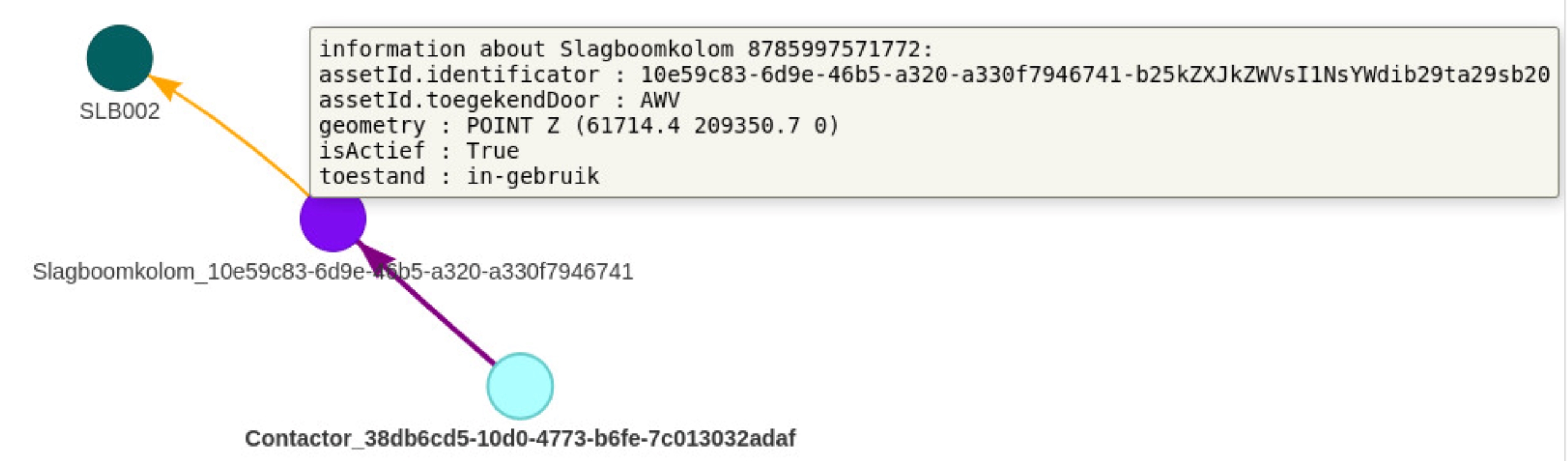
Er is ook de mogelijkheid om een interactief relatiediagram te genereren en een module om een automatische integratie met DAVIE te faciliteren. Tot slot kan je de Python bibliotheken gebruiken om plugins, voor bijvoorbeeld QGIS, te ontwerpen of ze mee te integreren in eigen ontwikkelde API’s. Hiervoor is wel meer ontwikkelkennis aangeraden.
Wil jij jouw OTL-conforme data beter beheren door Python? Bekijk dan zeker het project op https://github.com/davidvlaminck/OTLMOW-Model. Hier vind je de instructies om ermee aan de slag te gaan, de linken naar de andere modules en het notebook bestand dat je bijvoorbeeld in Google Colab kan gebruiken.